
Why EvalScribe Beats General AI Platforms for Writing Teacher Evaluations
Why EvalScribe Beats General AI Platforms for Writing Teacher Evaluations
Generative AI is showing up in school evaluation workflows whether districts have a plan for it or not. Some admins are quietly using ChatGPT to clean up walkthrough notes. Others are sitting through formal trainings where consultants teach them how to prompt their way to a standards-aligned write-up. Both approaches share the same premise: a general AI platform is good enough for the job of writing formal teacher evaluations.
It isn't. And the gap between "good enough" and "actually built for the work" is wider than most admins realize until they see the two side by side.
TL;DR: Generative AI is showing up in evaluation workflows, but not all AI is built for the work. A general platform like ChatGPT or Claude can produce decent evaluation language if you prompt it well — but every evaluation requires you to paste in standards, guide alignment, engineer the prompt, and edit the output. It also means your teachers' observation data is flowing through a general-purpose system that may use it to train future models. EvalScribe was built specifically for teacher evaluations. The primary frameworks for all fifty states are built in. Domain mapping and rubric-aware scoring happen automatically. The tool runs on Microsoft Azure with no data storage on our end — observation data doesn't sit on our servers. Some users report finishing an entire evaluation in under five minutes, and beta testers report saving 30 to 60 minutes per evaluation compared to writing them traditionally. The deeper difference isn't speed — it's defensibility and data protection. Consistent, framework-aligned outputs hold up in a personnel file. A purpose-built tool that doesn't retain your data holds up in a security review.
The short answer
A general AI platform is a blank room. You bring the standards, the rubric language, the framework alignment, the prompting expertise, and the editing skill. You assemble those things every time, for every evaluation, and the quality of the output depends on how well you assembled them that day.
EvalScribe is a purpose-built tool for one job — turning raw classroom observation data into formal, standards-aligned teacher evaluations. The standards are already loaded. The framework alignment is automatic. The rubric scoring is consistent. The output is evaluation-ready language, not first-draft prose that still needs work. Admins finish the entire evaluation in roughly five minutes. Compared to writing it without help, beta testers report saving 30 to 60 minutes per teacher.
That's the head-to-head. The rest of this post unpacks how we got here and why it matters.
The meeting that prompted this post
A district leader recently told me about a consultant his district had brought in to train school-level admins on using generative AI for teacher evaluations. He walked me through what the training covered — the prompting techniques, the workflow, the way admins were now supposed to draft and refine their evaluations using a general AI platform.
I listened. Then I explained, piece by piece, why that approach was going to cost his admins time they thought they were saving, why the outputs were going to be less defensible than the admins realized, and why a tool built specifically for evaluation work solves problems that prompting can't.
He asked me to write up a proposal for his district.
I'm not sharing that story to take a victory lap. I'm sharing it because the conversation made clear that a lot of well-meaning districts are about to spend a lot of admin time and energy on an approach that's going to disappoint them. There's a better way, and it's worth understanding why.
What general AI platforms actually do for evaluations
A general AI platform — ChatGPT, Claude, Gemini, Copilot — is a text generator. It will produce competent-sounding language about almost anything if you ask it the right way. That capability is real, and it's why so many admins have started experimenting.
But "competent-sounding language about almost anything" is not the same thing as "formal teacher evaluation aligned to a specific standards framework." To bridge that gap with a general platform, an admin has to do all of the following, every time, for every evaluation:
Write or paste in the framework standards (TKES, AQTS, Marzano, Danielson, or whatever the district uses)
Specify which domains the observation notes map to
Provide the rubric language so the AI knows what a 2 looks like versus a 3 versus a 4
Engineer the prompt well enough to produce evaluation-ready output instead of generic teacherly prose
Read the result carefully because the AI's scoring logic is inconsistent — it might rate the same observation differently across two admins, two prompts, or two days
Edit and reformat for the formal evaluation document
Repeat all of this for the next teacher
None of those steps is unreasonable in isolation. Stacked together, across forty teachers and three observations a year, they add up to a workflow that is slower and less consistent than what a busy admin actually needs.
What EvalScribe does differently
EvalScribe was built to do one thing exceptionally well: take an admin's raw classroom observation notes and produce a formal, standards-aligned teacher evaluation in minutes.
The standards are already in the tool. TKES is built in. So are AQTS, Marzano, Danielson, etc. In fact, the primary frameworks used in all 50 states are hardcoded into EvalScribe's brain. An admin opens the tool, drops in their notes, and the system handles the alignment, the domain mapping, and the rubric-aware scoring automatically. The output is formal evaluation language, written in the register that observation documents are actually expected to use.
There is no prompt to engineer. There is no framework to paste. There is no learning curve to climb. An admin can use EvalScribe well on day one without ever having taken a prompting workshop.
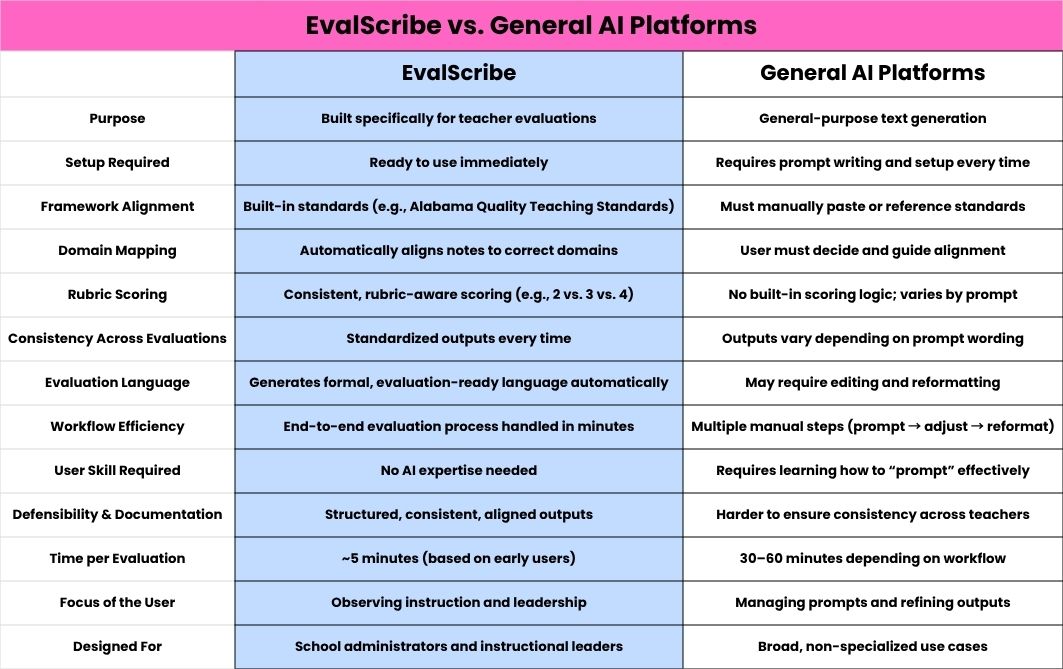
Side-by-side
The two approaches diverge in almost every dimension that matters for evaluation work.
Purpose and setup. EvalScribe is built specifically for teacher evaluations and is ready to use immediately. A general AI platform is designed for general-purpose text generation, which means every evaluation starts with prompt writing and setup work that has to be redone each time.
Framework and alignment. EvalScribe has the major standards frameworks built in — TKES, AQTS, Marzano, Danielson, and others — and automatically aligns observation notes to the correct domains. With a general platform, an admin has to manually paste or reference the standards, decide which domains apply, and guide the alignment themselves.
Scoring and consistency. EvalScribe applies consistent, rubric-aware scoring — the same logic for what a 2 looks like versus a 3 versus a 4, every time, across every admin in the building. A general platform has no built-in scoring logic. Outputs vary depending on prompt wording, which means two admins evaluating similar observations can land in substantively different places.
Output and language. EvalScribe generates formal, evaluation-ready language automatically. A general platform produces prose that often requires editing and reformatting before it can be dropped into a personnel file. The end-to-end evaluation process in EvalScribe takes minutes; the same work in a general platform involves multiple manual steps — prompt, adjust, reformat, repeat.
Skill required and time per evaluation. EvalScribe requires no AI expertise. A general platform requires learning how to prompt effectively, and that skill decays without regular practice. Some EvalScribe users report completing an entire evaluation in under five minutes; beta testers report saving 30 to 60 minutes per evaluation compared to writing them traditionally.
Defensibility and focus. EvalScribe produces structured, consistent, aligned outputs that hold up in a personnel file. A general platform makes it harder to ensure consistency across teachers and across admins — exactly the consistency that formal rubrics exist to protect. The deeper difference: with EvalScribe, an admin's focus stays on observing instruction and leadership. With a general platform, the admin's focus shifts to managing prompts and refining outputs. EvalScribe was designed for school administrators and instructional leaders doing real evaluation work. A general AI platform was designed for broad, non-specialized use cases.
Why this matters beyond convenience
A faster workflow is nice. The deeper issue is defensibility.
A teacher evaluation is not a casual document. It lives in a personnel file. It informs contract decisions, professional growth plans, and, sometimes, dismissal proceedings. When an evaluation is challenged — by a teacher, by a union representative, by an attorney — the question is whether the document holds up. Whether the scoring is consistent across teachers and across admins. Whether the language aligns to the framework the district has formally adopted. Whether the same observation, written up twice, would land in the same place.
A general AI platform cannot guarantee any of that. The output depends on the prompt, the day, the model version, and the admin's skill in steering it. Two admins evaluating two similar observations might land on substantively different scores and substantively different language. That's not a hypothetical concern. That's a personnel file waiting to be challenged.
EvalScribe was built with that defensibility problem in mind. The same framework, the same rubric logic, the same scoring approach, every time. An admin's voice and judgment still drive the evaluation — they're the ones in the classroom doing the observation — but the document that emerges is structurally consistent across the building and across the district.
What the consultant training misses
When a consultant teaches admins to use general AI for evaluations, what they're really teaching is prompt engineering. The framing is usually some version of: learn to prompt well, and you can make the AI do anything you need.
That's true, in a narrow sense. A skilled prompter can get strong evaluation language out of a general platform. But three things tend to go unsaid in those trainings.
First, prompt engineering is a skill that decays without practice. An admin who learns it in a workshop and then writes evaluations twice a year is not going to retain that skill. They'll fall back to mediocre prompts and mediocre outputs, and they won't necessarily realize the quality has dropped.
Second, the time the AI "saves" is partially absorbed by the time spent prompting, reviewing, and reformatting. The net time savings are real but smaller than advertised, and they shrink further as the admin's prompting muscle weakens.
Third, and most importantly, prompt engineering doesn't solve the consistency problem. Even a skilled prompter produces variation across evaluations, across teachers, and across admins. The whole reason districts adopt standardized rubrics is to minimize that variation. A workflow that reintroduces it through the AI layer is working against the rubric's purpose.
I'm not anti-AI in evaluation workflows. I'm anti the assumption that any AI is equivalent to AI built for this specific job. The tool matters. The tool you choose for this work should be designed for this work.
What admins should actually evaluate
If you're a district leader looking at AI options for teacher evaluations, here are the questions worth asking — about any tool, including EvalScribe.
Is the framework built in, or do my admins have to provide it? If they have to provide it, the workflow is fragile. People paste the wrong version, skip a domain, miss an update.
Is the scoring consistent across admins? Ask to see two admins run the same observation through the tool and compare the outputs. If they diverge meaningfully, the tool isn't actually solving the consistency problem.
How long does an admin spend per evaluation, end to end? Not "how long does the AI take to respond" — how long from opening the tool to having a final evaluation in the personnel file.
What happens to the data? Where is it stored? Who can see it? Is the vendor using your teachers' observation data to train a model? EvalScribe is built on Microsoft Azure with no data storage on our side, which matters to a lot of districts.
Can my admins use it on day one without training? If the answer is no, factor the training cost — money and time — into your decision.
What does it actually cost, per admin and per year? Procurement matters. EvalScribe is launching at $100 per year per individual admin, $90 per admin for school-wide licenses with three or more admins, and $80 per admin for district-wide licenses. That price point is intentional. It sits below most procurement thresholds, which means an individual admin can decide to try it without waiting for a committee.
The mission underneath all of this
The reason EvalScribe exists is straightforward. The mission is to help make lives better by automating tasks so people can be physically and mentally present.
Admins who love being in classrooms shouldn't have to dread the paperwork that follows. Teachers who deserve thoughtful, framework-aligned feedback shouldn't get whatever fell out of a Sunday-night prompt-engineering session. Districts that have invested years in building a coherent evaluation framework shouldn't watch it dissolve at the AI layer.
The translation tax between raw observation and formal evaluation is real. A general AI platform reduces it. A purpose-built tool eliminates it. That's the difference.
FAQ
Can I just use ChatGPT or Claude to write teacher evaluations? You can. The question is whether the output is consistent, framework-aligned, and defensible across admins and across teachers — and whether the time savings are real once you account for prompting, editing, and reformatting. For most admins doing this work seriously, a purpose-built tool gets there faster and more reliably.
What frameworks does EvalScribe support? Click here to see a complete list of our current supported evaluation frameworks. If your district uses a framework not currently in the tool, reach out — [email protected] — and we'll talk.
Does EvalScribe store our observation data? No. EvalScribe is built on Microsoft Azure with no data storage. Your observations don't sit on our servers.
How much does EvalScribe cost? EvalScribe is launching at $100 per year for individual admins. $90 per admin for school licenses (three or more admins). $80 per admin for district-wide licenses.
How long does an evaluation actually take? Some users report completing an entire evaluation in under five minutes. Compared to writing one traditionally, beta testers report saving 30 to 60 minutes per evaluation. Now multiply that times 40, 50, 60+ teachers, who each have multiple evaluations per year, and it becomes obvious the sheer amount of time you will save throughout the school year.
Do my admins need AI training to use EvalScribe? No. EvalScribe was designed so an admin can use it well on day one without a workshop, a certification, or a prompt-engineering primer. However, our team is always glad to help however we can.
Where can I learn more or set up a demo? Email [email protected].
